“R, at its heart, is a functional programming (FP) language. This means that it provides many tools for the creation and manipulation of functions. In particular, R has what’s known as first class functions. You can do anything with functions that you can do with vectors: you can assign them to variables, store them in lists, pass them as arguments to other functions, create them inside functions, and even return them as the result of a function.” - Hadley Wickham
Don’t need to write for-loops! - check this video.
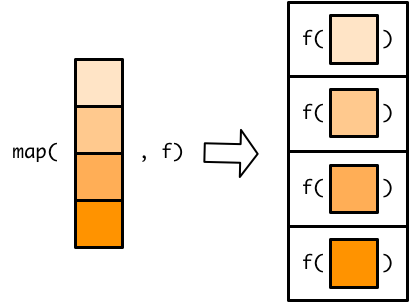
Allows you to flexibly iterate functions to multiple elements of a data object!
Useful when you want to apply a function to:
* lots of columns in a tibble
* multiple tibbles
* multiple data files
* or perform fancy functions with vectors (or tibble columns)
 [
[